HashMap 示意代码
MyHashMap.java 模拟实现源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| public class MyHashMap<K,V> {
private final int INIT_CAPACITY=1000;
private Node<K,V> [] container = new Node[INIT_CAPACITY];
public MyHashMap(){
}
public void put(K key,V value){
int code = key.hashCode()>>2;
Node<K,V> oldNode = container[code];
if(oldNode == null){
Node<K,V> node = new Node<K,V>();
node.hashCode = code;
node.key=key;
node.value = value;
container[code] = node;
}else{
K oldKey = oldNode.key;
if(oldKey.equals(key)){
oldNode.value=value;
}else{
Node<K,V> node = new Node<K,V>();
node.hashCode = code;
node.key=key;
node.value = value;
oldNode.next=node;
}
}
}
public Object get(K key){
int code = (key.hashCode()>>2);
return container[code].value;
}
}
class Node<K,V>{
int hashCode;
K key;
V value;
Node<K,V> next;
}
|
Test.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| package com.neu.day08._06map;
public class Test {
public static void main(String[] args) {
MyHashMap<User, String> data = new MyHashMap<>();
User one = new User(100);
data.put(one, "xx");
User two = new User(100);
data.put(two, "yy");
}
}
class User{
int num;
public User(int num){
this.num = num;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + num;
return result;
}
}
|
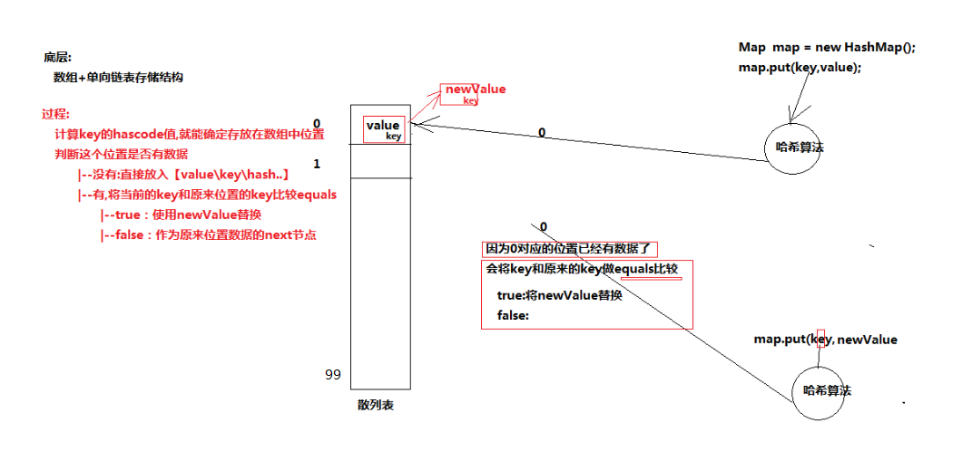
过程:
- 计算key的哈希code值,就能确定存放在数组中的位置。
- 然后判断这个位置是否有数据。
- 有两种情况:其一是没有数据,直接放入[value, key, ,hash]; 其二:有,将当前的key和原来位置的key调用equal方法比较,为true就使用newValue替换,为false就作为原来位置数据的next节点。
HashMap底层实现原理及面试问题
①HashMap的工作原理
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,
它调用键对象的hashCode()方法来计算hashcode,然后找到bucket位置来储存值对象
。当获取对象时,通过键对象的 equals() 方法找到正确的键值对,然后返回值对象。
HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
当两个不同的键对象的hashcode相同时会发生什么? 它们会储存在同一个bucket位置的链表
HashMap
HashMap实现了Map接口,Map接口对键值对进行映射。Map中不允许重复的键。Map接口有两个基本的实现,HashMap和TreeMap。
含义
key-value形式
底层
数组+链表
示意图
体系结构
常用方法
- size
- put
- putAll
- get
- size
- isEmpty
- clear
- containsKey
- containsValue
- remove
- 等等
案例一
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| public class _01HashMapDemo {
public static void main(String[] args) {
HashMap<String,String> data = new HashMap<>();
data.put("name","zs");
data.put("age","10");
data.put("address","guangzhou");
System.out.println(data.get("name"));
data.remove("age");
System.out.println(data);
System.out.println(data.containsKey("name"));
System.out.println(data.containsValue("zs"));
System.out.println(data);
Map<String,String> temp = new HashMap<>();
temp.put("color", "red");
temp.put("size", "xl");
data.putAll(temp);
System.out.println(data);
System.out.println(data.size());
}
}
|
案例二
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| public class _02HashMapDemo {
public static void main(String[] args) {
HashMap<String,String> data = new HashMap<>();
data.put("name","zs");
data.put("age","10");
data.put("address","guangzhou");
System.out.println("方式一................");
Set<String> keys = data.keySet();
for(String key : keys){
System.out.println(key+"="+data.get(key));
}
System.out.println("方式二................");
Collection<String> values = data.values();
for(String value : values){
System.out.println(value);
}
System.out.println("方式三................");
Set<Entry<String, String>> entrySet = data.entrySet();
for(Entry<String, String> entry : entrySet){
System.out.println(entry.getKey()+"="+entry.getValue());
}
}
}
|
案例三
验证HashMap是否有序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public class _03HashMapDemo {
public static void main(String[] args) {
Map<String,String> data = new HashMap<>();
data.put("33","33");
data.put("hhhhhh","33");
data.put("aa","aaaa");
data.put("xx","xxxx");
data.put("yy","yyyy");
data.put("yy","1000");
data.put("11","11");
data.put("22","22");
System.out.println(data);
}
}
|
LinkedHashMap
含义
有序的hashMap
体系结构
案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| public class _04LinkedHashMap {
public static void main(String[] args) {
Map<String,String> data = new LinkedHashMap<>();
data.put("33","33");
data.put("hhhhhh","33");
data.put("aa","aaaa");
data.put("xx","xxxx");
data.put("yy","yyyy");
data.put("yy","1000");
data.put("11","11");
data.put("22","22");
System.out.println(data);
}
}
|
Hashtable
含义
重量级HashMap,用法和HashMap类似
体系结构
和HashMap的区别
- Hashtable的方法几乎都有synchronized【线程安全】
- HashMap的key和value都是可以为null,Hashtable的key和value都不可以为空
案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| public class _05HashtableDemo {
public static void main(String[] args) {
Hashtable<String,String> data = new Hashtable<>();
data.put("xx", "xxxx");
data.put("yy", "yyyy");
data.put("zz", "zzzz");
System.out.println(data);
HashMap<String,String> xx = new HashMap<>();
xx.put(null,null);
}
}
|
面试题:
“你知道HashMap的工作原理吗?” “你知道HashMap的get()方法的工作原理吗?”
但一些面试者可能可以给出答案,“HashMap是基于hashing的原理,我们使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。
当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,返回的hashCode用于找到bucket位置来储存Entry对象。”这里关键点在于指出,HashMap是在bucket中储存键对象和值对象,作为Map.Entry。
这一点有助于理解获取对象的逻辑。如果你没有意识到这一点,或者错误的认为仅仅只在bucket中存储值的话,你将不会回答如何从HashMap中获取对象的逻辑。这个答案相当的正确,也显示出面试者确实知道hashing以及HashMap的工作原理。
下个问题可能是关于HashMap中的碰撞探测(collision detection)以及碰撞的解决方法:
“当两个对象的hashcode相同会发生什么?”
答:他们有equals()和hashCode()两个方法,并且两个对象就算hashcode相同,但是它们可能并不相等。因为hashcode相同,所以它们的bucket位置相同,‘碰撞’会发生。因为HashMap使用链表存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在链表中。
”这个答案非常的合理,虽然有很多种处理碰撞的方法,这种方法是最简单的,也正是HashMap的处理方法。但故事还没有完结,面试官会继续问:
“如果两个键的hashcode相同,你如何获取值对象?”
面试者会回答:当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,然后获取值对象。面试官提醒他如果有两个值对象储存在同一个bucket,他给出答案:将会遍历链表直到找到值对象。面试官会问因为你并没有值对象去比较,你是如何确定确定找到值对象的?除非面试者直到HashMap在链表中存储的是键值对,否则他们不可能回答出这一题。
其中一些记得这个重要知识点的面试者会说,找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象。完美的答案!
许多情况下,面试者会在这个环节中出错,因为他们混淆了hashCode()和equals()方法。因为在此之前hashCode()屡屡出现,而equals()方法仅仅在获取值对象的时候才出现。
一些优秀的开发者会指出使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法的话,将会减少碰撞的发生,提高效率。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择。
如果你认为到这里已经完结了,那么听到下面这个问题的时候,你会大吃一惊。
“如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?”
除非你真正知道HashMap的工作原理,否则你将回答不出这道题。默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
如果你能够回答这道问题,下面的问题来了:
“你了解重新调整HashMap大小存在什么问题吗?”
你可能回答不上来,这时面试官会提醒你当多线程的情况下,可能产生条件竞争(race condition)。
当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。
如果条件竞争发生了,那么就死循环了。这个时候,你可以质问面试官,为什么这么奇怪,要在多线程的环境下使用HashMap呢?)
HashMap底层实现原理及面试问题: https://blog.csdn.net/suifeng629/article/details/82179996?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1-82179996-blog-89480637.pc_relevant_multi_platform_whitelistv3&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1-82179996-blog-89480637.pc_relevant_multi_platform_whitelistv3&utm_relevant_index=1